Privacy + transparency in myGaru: security engineering perspective
Mar 12, 2021

My day-to-day job is running a company that has to find 100% formally correct ways to protect the data within heavily regulated industries (finance, healthcare, govtech, critical infrastructure) and companies that face high risks associated with operating sensitive data. Yet, when you think about a typical adtech business and shady data usage practices, security concerns would be the last thing that comes to mind, right?
myGaru has invited us to invest our expertise to build a system that respects the privacy rights of users and avoids common security pitfalls that enable fraud and misuse by various parties in the system. That means getting a lot of things right in many cases.
A road paved with challenges
Technological challenges of enforcing citizen rights in next-gen transparent adtech systems are:
Beating the ecosystem fragmentation by building a unified data infrastructure and data security layer protecting it across its lifecycle.
Instilling platform trust by building an externally auditable system that provides evidence of responsible data usage and security subsystem functioning.
Coordinating that with traditional security controls and their place in the ecosystem.
From a business risk perspective, preventing fraud is the biggest challenge that has no good legal solutions until you at least have direct evidence of all commercially-sensitive transactions:
We need a full end-to-end adtech ecosystem built with the idea of transparency by design, fully eliminating any hidden commissions, avb’s or unfair revshares. Making every step in transactions fully auditable. Solving the SPO problem and therefore solving the fraud issues.
This also requires a revolutionary approach to data, based on per-usage fees, bringing the real value of the data to any advertisers, with a holistic approach to data sources and algos. This approach makes data accessible to everyone while keeping it totally safe and anonymous, with full transparency of usage, billing and internal data-flow.
Just connecting together all the facets of the ecosystem, from the user to the bidding and targeting platform, is insufficient. myGaru strives to enforce correct behavior between the entities, and the audit logging system we’re building comes in handy: aside from having a tamper-proof audit log for our security purposes, extending it to be externally verifiable, transparent to all parties participating in the system is a must.
We’re no strangers to these challenges in traditional industries - different breeds of aforementioned controls are pretty typical for high-risk banking and payment processing systems, but adtech is typically seen as “speed and capacity above all” type of systems. Network latency vs Bid success is crucial, being able to process humongous amounts of data on reasonably cheap hardware solutions, etc.
So, how do we build high-class security tooling that covers the data lifecycle, provides transparency for everyone yet does not constrain key performance metrics?
Key design considerations
The challenges above dictate tricky design decisions, so prior to jumping to exciting tech details, it’s worth seeing them together, contextualised against the two biggest design goals - security and transparency.
Security
Secure from day 0, secure by default: the easiest way to make developers adhere to security requirements is to weave them into the fabric of their software. Building fundamental security controls along with the actual software, making secure ways to process the data and log events to be the only ways present in the system is hard. Yet, this makes developers base their decisions on an already-functioning security layer.
Balancing risk-driven security choices with performance and architecture considerations. Building encryption everywhere sounds good only if you haven’t built tooling for sophisticated encrypted data flows in the past. Frequently it’s slow, cumberstone, or leaky, or extremely expensive. Most of the time it’s all of these. We limit encryption to places where it's necessary and justified by security controls, and avoid additional encryption where performance is crucial. We use anonymised datasets, stripped of PII, as much as we can, and make sure we can prevent them from being deanonymised.
From a performance perspective, even anonymised datasets impose sufficient performance penalties to use them in matching, so organising a system in a way that anonymisation, encryption and inference control measures are applied transparently is essential for developers to build efficient workflows on top of that.
Control on choke points. Every good security layer has a bunch of choke points - gates, boundaries, “locations”, which enforce security decisions (friend, foe, level of access, etc.). Since we’ve got very few points with PII, we want very few choke points in front of PII and enough transparency logging on any PII access to deal with sensitive data risks.
Identification and inference control. Some of the unique prominent risks of adtech is inference attacks and cross-identification. We employ some of the classic tools for inference control: rotating anonymising credentials, using central matching points of random tokens, query control for size and tracker queries (queries that indirectly deanonymise a person). Statistical security is a discipline with very limited efficiency of each measure, known to leak low-entropy values regardless of measures, thus building a sophisticated, multi-method inference protection suite is a long-term goal that will limit inference/deanonymisation/unauthorised enrichment where possible.
Transparency
Security + visibility + transparency. Security without visibility is a myth in any system. Yet, in our case, visibility exists not just for the sake of peace of mind of risk stakeholders, but as a means for system participants to validate the system’s honesty. Pretty much like trusting blockchain because the trust is decentralised by design, we wanted to have a decentralised, verifiable audit trace shared among all participants: at any moment in time, willing parties should be able to validate correctness of security logs and business logs.
Verifiable trust. To make sure that transparency is a first-class attribute of the system, we want everything to be verifiable: users and partners don’t have to trust myGaru to trust myGaru’s logs and activities.
This means using only vetted, community reviewed cryptographic primitives and implementations, cryptosystems and security methods that have a good track record in the industry already: building a system this big, then pushing it against auditors and letting it float for a while gives too little confidence for all parties.
This also means having strong cryptographic proofs for all system’s logs - on the technical and business layer, emitting these proofs in blockchain-like data structures to 3rd party observers and enabling them to monitor the system’s correct behavior and log transactions via cryptographic proofs.
Well-rounded stack
What we strive for is not just to have a set of efficient security controls - we strive for strong control coverage, that co-exists with the main system and makes it secure. We base most controls on strong cryptography with cryptographic proofs available to observers - so that “trust myGaru servers”/”trust myGaru operator honesty” is not an implicit requirement towards “trust the myGaru ecosystem”, just like most decentralised systems we love. Only with a caregiving administrator entity.
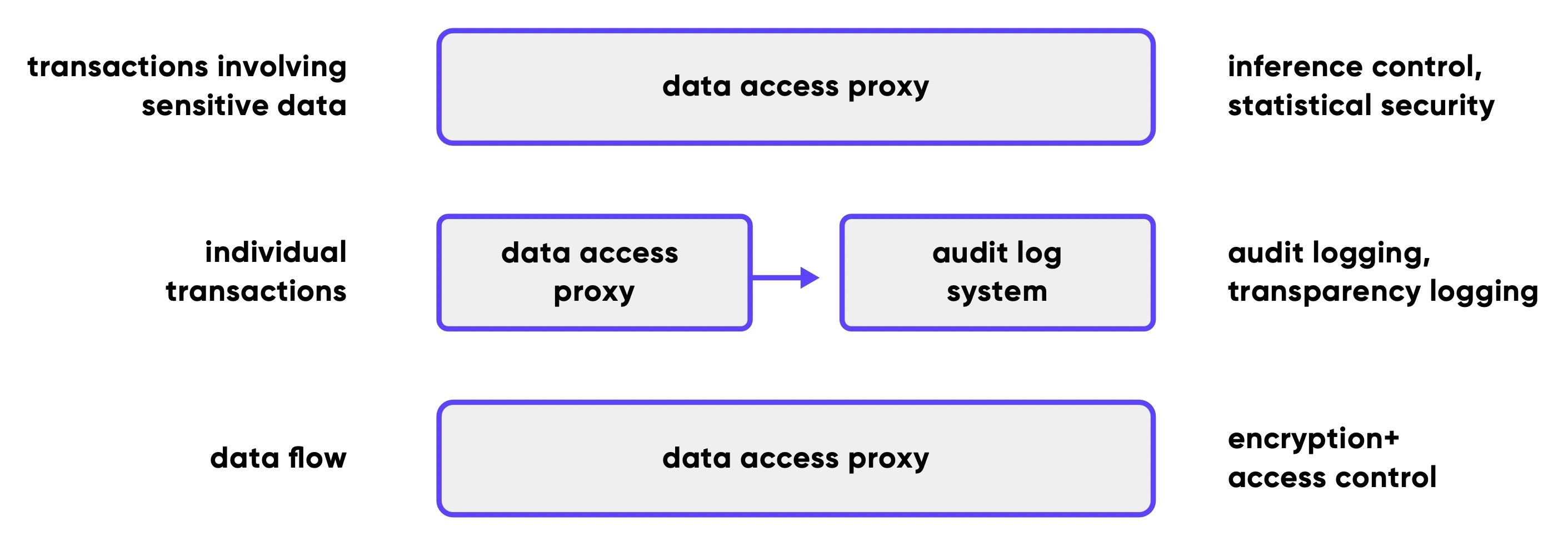
Data layer: Single-entry proxy for every sensitive data store provides PII encryption, access control, audit logging and part of the statistical security suite.
We use one strong choke point - access to the data in corresponding - to do encryption/decryption of sensitive data, key management, access control and generate anonymised datasets while controlling inference. We do that via application-level data access proxy, that is separate from all application code. Bypassing it is pointless, because accessing plaintext values requires having keys and access to encryption logic, which is encapsulated in the proxy.
Being a gentle twist on the traditional DAO pattern in the modern microservice world, this approach provides enough security enforcement while leaving us with enough space for scaling and optimisation.
Identification layer: We run a set of classical inference control and statistical security tools that span across proxy, identification service and ID generation service.
Using frequent anonymous credential rotation and query control (to avoid inference and tracking queries) is just a baseline to ensure that obvious attacks are mitigated. Looking into the future, we’re building specialised approaches to enable mass analysis without access to individual data (akin to Differential Privacy) and other means of bypassing the limitations of traditional statistical security.
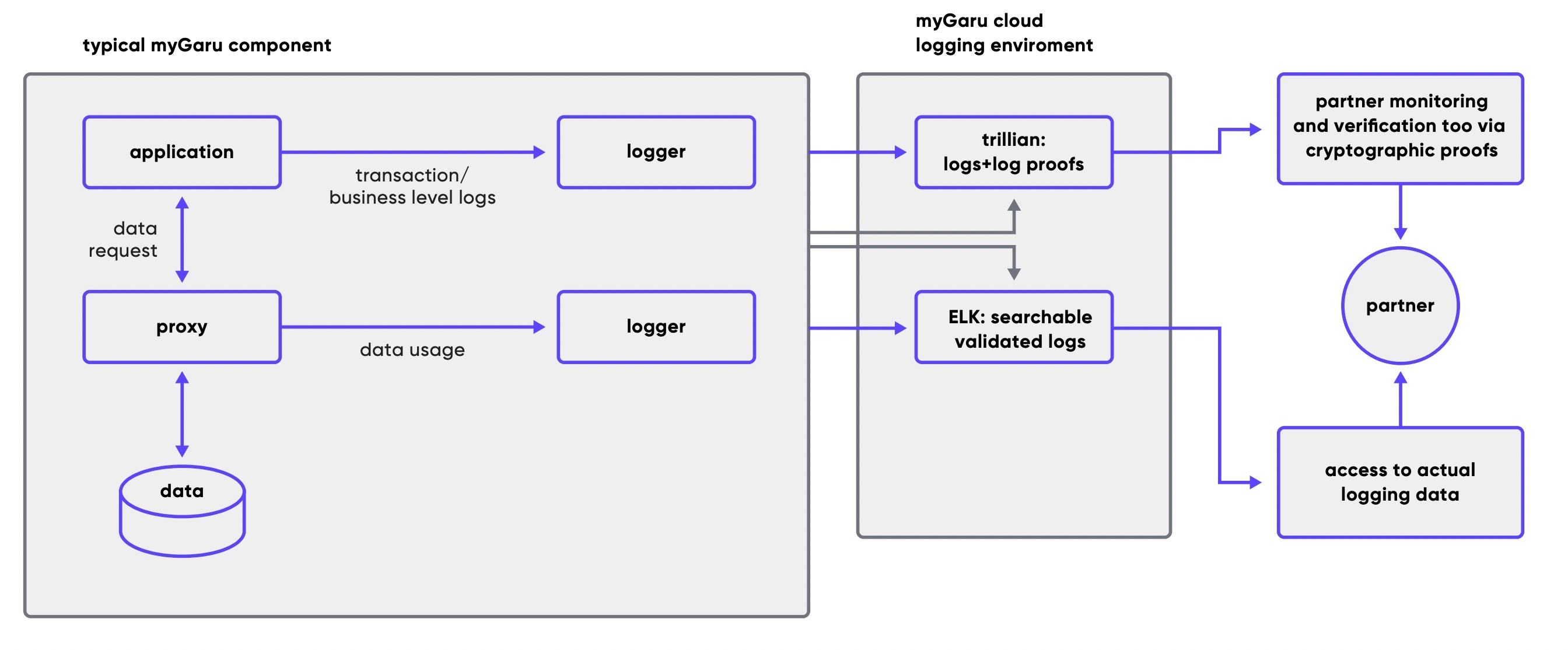
Auditability and transparency: every data access event, as well as every business logic event, is recorded to a centralised audit log on various levels and cross-verified when needed. Our audit log system is built around RFC 6962 - event logging protocol that powers TLS certificate issuing trust. Its implementation is built around Google’s Trillian server and additional tooling for 3rd party verifiers, verification during writes and verification on the logger side, reinforcing and extending security guarantees of the already well-known and trusted audit logging scheme.
From a user-level perspective, we rely on having the log trusted by all parties and then recovering/verifying sequence of events from the trusted log to verify them.
In the future, when parts of the data flow will be more final, an additional layer of verification during log ingestion (does sequence of transactions match expected state machine) and two-step auditable transactions (log “planning to do”, do only if “planning log” is present, the log “actually done”) will be turned on to make sure that not only we see the actual sequence of events,- but that some events will raise alarms before the user notices discrepancies.
The future
We’re only treading in this water - in fact, there are further challenges down the road that already require more work, more effort and more experimentation.
For example, what lies next in our scientific journey is
having provable user consent that is applied efficiently to every transaction with user data, basically letting the user decide ACL to his data that myGaru operates on and then applying it in a performant and mathematically provable way.
Having on-the-fly validation of business logic validity in audit logs to immediately detect logical faults and raise security alerts during incidents, not post-factum during billing reconciliation.
myGaru is uniquely positioned to tackle them, and many other challenges ahead simply because controlling the whole ecosystem and being legally responsible for being a responsible controller puts myGaru in a position where no other options are available anyway.